Hesam Seyed Mousavi, April 22, 2024
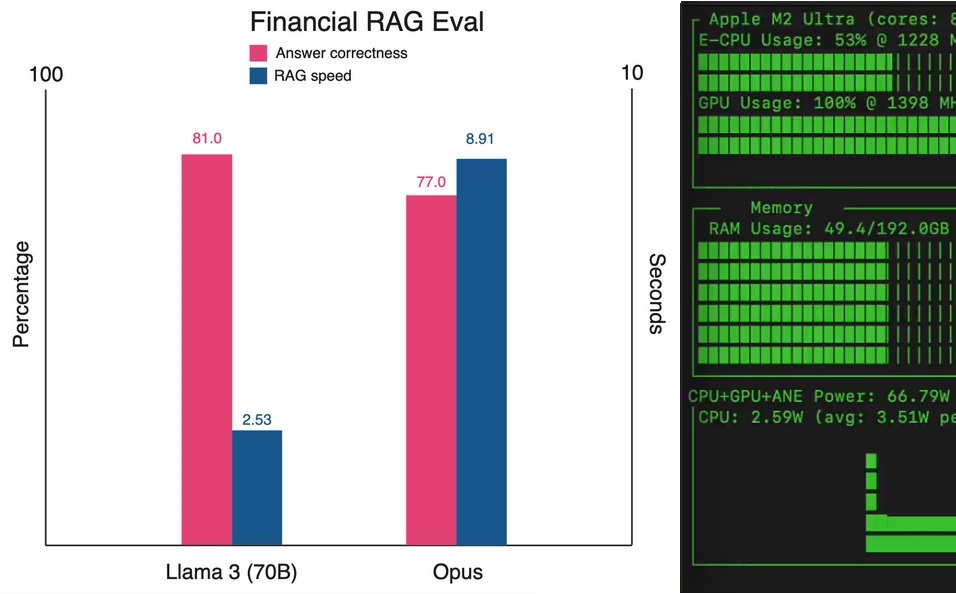
The 70b model beat opus on my financial RAG tests. Llama 3 RAG results: • speed: 2.59s • correctness: 81.33% This is the highest score I have seen on financial RAG. • 7 secs faster than opus • 4% more correct than opus With insane inference speed from Groq, the comparison with opus almost feels unfair. Both models had to answer 100 questions from an SEC filing dataset. Both models had the same RAG setup, including vector DB indexing, retrieval, and reranking. Both models were evaluated by a human (me). The speed and quality of llama 3 + groq is terrific.
import getpass
import os
Set your Groq API key
os.environ[“GROQ_API_KEY”] = getpass.getpass()
Set your Cohere API key
os.environ[“COHERE_API_KEY”] = getpass.getpass()
Set your OpenAI API key
os.environ[“OPENAI_API_KEY”] = getpass.getpass()
!pip install -U -q langchain cohere ragas arxiv pymupdf chromadb wandb tiktoken unstructured==0.12.5 datasets openai pandas groq
Download SEC filing
from langchain_community.document_loaders import UnstructuredURLLoader
url = “https://www.sec.gov/Archives/edgar/data/1559720/000155972024000006/abnb-20231231.htm”
loader = UnstructuredURLLoader(urls=[url], headers={‘User-Agent’: ‘virat virat@virat.com’})
documents = loader.load()
Chunk and store filing in vector DB
from langchain.vectorstores import Chroma
from langchain.text_splitter import TokenTextSplitter
from langchain.embeddings import OpenAIEmbeddings
Naively chunk the SEC filing by tokens
token_splitter = TokenTextSplitter(chunk_size=256, chunk_overlap=20)
docs = token_splitter.split_documents(documents)
Save the chunked docs in vector DB
vectorstore = Chroma.from_documents(docs, OpenAIEmbeddings(model=”text-embedding-3-large”))
Load Q&A Dataset
import requests
import pandas as pd
URL of the JSON file
url = ‘https://raw.githubusercontent.com/virattt/datasets/main/abnb-2023-10k.json’
Fetch the JSON content from the URL
response = requests.get(url)
data = response.json()
Convert the JSON content to a pandas DataFrame
df = pd.json_normalize(data)
Rename ‘answer’ to ‘ground_truth’ for eval later one
df.rename(columns={‘answer’: ‘ground_truth’}, inplace=True)
Display the DataFrame
df.head()
Generate answers using LLM
prompt = “””
You are an expert language model designed to
answer questions about financial documents like
SEC filings.
Given financial documents, your primary role is to extract key information
and providing accurate answers to questions
related to these filings.
In your response, optimize for conciseness, accuracy, and correctness.
“””
from typing import List
from groq import Groq
import cohere
co = cohere.Client(os.environ[“COHERE_API_KEY”])
client = Groq(api_key=os.environ.get(“GROQ_API_KEY”))
def rerank_documents(query: str, documents: list, top_k) -> List[str]:
response = co.rerank(
query=query,
documents=documents,
top_n=top_k,
model=”rerank-english-v3.0″,
return_documents=True
)
results = response.results
return [{“text”: docs.document.text} for docs in results]
def answer_question(query: str, documents: list, prompt: str) -> str:
response = client.chat.completions.create(
messages=[
{
“role”: “system”,
“content”: prompt,
},
{
“role”: “user”,
“content”: f”Please answer the question: {query} given the context: {documents}.”,
},
],
max_tokens=4096,
temperature=0.0,
model=”llama3-70b-8192″,
)
return response.choices[0].message.content
import time
answers = []
k = 3
Fields for computing inference speed
total_time = 0.0
num_iterations = 0
Execute RAG pipeline
for index, row in df.iterrows():
# Get start time
start_time = time.time()
# Extract the question
question = row[‘question’]
# Print current question
print(f”Answering question {index + 1}: {question}”)
# Query vector DB for documents
top_k_docs = vectorstore.similarity_search(question, k)
# Extract the text content from documents
documents = [{“text”: doc.page_content} for doc in top_k_docs]
# Rerank the documents
documents = rerank_documents(question, documents, k)
# Ask the LLM
answer = answer_question(question, documents, prompt)
# Add generated answer to our list of answers
answers.append(answer)
# Get end time
end_time = time.time()
# Update total execution time (excluding sleep time)
total_time += (end_time – start_time)
num_iterations += 1
# Sleep for 4 second to avoid overloading the LLM
time.sleep(4)
Add the generated answers as a new column in the DataFrame
df[‘answer’] = answers
Calculate the average execution time
avg_time = total_time / num_iterations
print(f”Took {avg_time} avg seconds for each RAG call”)
Visually inspect the answers
df.head()
Evaluate results
import json
Selecting only the required columns
df_subset = df[[‘question’, ‘ground_truth’, ‘answer’]]
Converting to JSON format
json_str = df_subset.to_json(orient=’records’)
Convert JSON string to dictionary
json_dict = json.loads(json_str)
Manually evaluate the results
pretty_json = json.dumps(json_dict, indent=2)
print(pretty_json)


